
Guten Tag zusammen,
Anschließend an meinen letzten Community-Artikel wollte ich noch ein paar weitere Daten zur Untermauerung der Hyperbel-Theorie vorlegen. Schauen wir uns hierfür ein schon länger bestehendes Onlineportal im Vergleich an:
Verwendetes Programm: Excel
Verwendete Daten:
1.) Letsrockmathe (kurz LRM): gleiches Datenset wie im letzten Artikel verwendet, STAND - 15.08.2019 - ca. 17:00:
etwa 7900 Mitglieder, ca. 4400 gezählte Antworten, nur Ränge und Punktzahlen ausgewertet (da noch zu noch wenige Daten zu den Antworten vorliegen...): Gruppe diesmal - Top 300
2.) MatheBoard (kurz MB): STAND - 21.08.2019 - ca. 14:00 Uhr:
Mitglieder: 74.953 | Themen: 261.263 | Beiträge: 1.845.236 | erste Mitglieder: April 2003
Ränge und die Beitragsanzahl verwendet (da keine Punktewertung vorzuliegen scheint): Gruppe ebenfalls - Top 300
Aufgrund dieser Unterschiede in der Datenerhebung ist nur bedingte Vergleichbarkeit gegeben. Da aber zuletzt bereits gezeigt wurde, dass Punkte und Antworten in Letsrockmathe zumindest signifikant korrelieren, ergibt sich immerhin eine Näherung für eine mögliche weitere Entwicklung.
Zunächst will ich einige Fakten in Erinnerung bringen.

Abbildung 1 - Statistische Übersicht LRM
Es gilt nun für MatheBoard, dass die Top 300 (mit einem Anteil von 0,4% an allen Mitgliedern) immerhin 41,6% aller Beiträge (Fragen und Antworten, wobei hier klar die Antworten überwiegen dürften) verfassen.
Unterteilt man auch diese Gruppe (wie zuletzt in Letsrockmathe geschehen), verfassen hierbei (bezogen auf die Top 300) die Gruppen folgende Anteile (41,6% entspricht 1)
die Top 5 - 0,196 ; die Top 15 - 0,390 ; die Top 40 - 0,617 ; die Top 100 - 0,814.
Es sollte trotz dieser recht groben Daten offensichtlich sein, dass die Verteilung der Beiträge von MatheBoard flacher ist. Es ist also ein insgesamt größerer Teil an allen (aktiven) Nutzern für die Beantwortung eines signifikanten Anteils von Fragen notwendig.
Zudem gibt es keine derart extremen Startausreißer (bei LRM sahen wir immer deutlich die zwei höchsten Punkt- und Antwortzahlen herausstechen). Ein Hinweis auf eine "natürlichere" Verteilung. Und bevor jemand noch etwas Falsches denkt: Ich weiß selbstverständlich auch, dass die Bezugsgröße bei LRM 112 war, bei MB jetzt 300 ist. Dennoch haben die Top 5 bei LRM z.B. einen höheren Wert als die Top 15 bei MB.
Es lohnt sich meiner Meinung nach aber nicht, hier genauer aufzuschlüsseln, solange bei Letsrockmathe nur Antwortdaten von 112 Nutzern vorliegen.
Doch worum soll es jetzt eigentlich gehen? Ist es nun möglich die Beitragsverteilung bei MB ebenfalls durch Hyperbeln zu beschreiben, wie uns das bei LRM mit den Punkten gelungen war?
Stellen wir dazu die Daten grafisch gegenüber:

Abbildung 2 - LRM Punkte: Normal und Logarithmisch - Top 300

Abbildung 3 - MB Beiträge: Normal und Logarithmisch - Top 300
Auch hier lässt sich auf den ersten Blick erkennen, dass vermutlich Hyperbeln vorliegen.
Wenden wir nun unser erlangtes Wissen über LRM auf MB an und beginnen mit der Linearisierung.
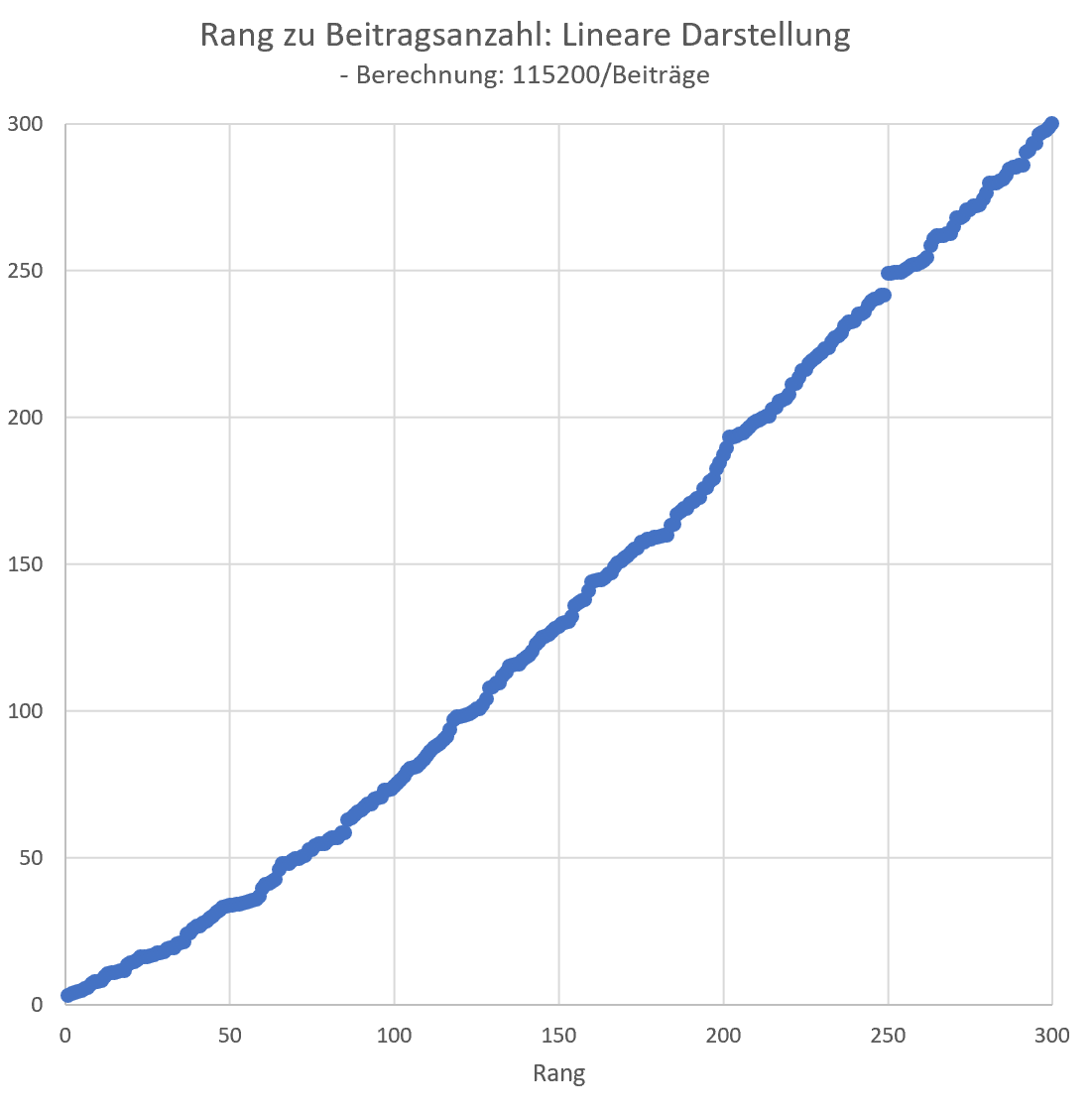
Abbildung 4 - Linearisierte Darstellung der Beitragszahlen
Offensichtlich muss auch hier zwischen einer Topgruppe (etwa Rang 1-85) und einer Restgruppe (etwa Rang 85-300) unterschieden werden.
Bestimmen wir die Regressionsgeraden:

Abbildung 5 - Regression 1-85

Abbildung 6 - Regression 85-300
Die Regressionen sind von hoher Güte, wobei für die Gruppe 85-300 fast das Bestimmtheitsmaß 1 erreicht wird. In der Top 85 Gruppe wären trotz der auf den ersten Blick guten Näherung mit einer Ursprungsgerade aber nicht hinnehmbare Fehler zu erwarten. Dies wäre vor allem für die Top 10 Gruppe der Fall, da in diesem (aufgrund der Hyperbel-Funktion) "kritischen" Bereich Abweichungen von der Regression teils extreme Fehler verursachen. Daher muss hier besondere Vorsicht gelten und somit weder eine Ursprungsgerade noch die eigentlich beste Regression gewählt werden. Ein sinnvolles Ergebnis erhält man mit etwas Übung recht einfach - der Beweis, dass man nun aber wirklich die "beste" Lösung gefunden hat, erfordert aber unvertretbaren Aufwand. Man müsste hierzu die prozentualen Abweichungen der Daten von der Rekonstruktion der Beitragszahlen für alle möglichen linearen Regressionen bestimmen und sinnvoll gewichten sowie anschließend minimieren. Die geringfügigen Verbesserungen erscheinen mir den Aufwand aber nicht wert zu sein.
Man konstruiert nun noch wieder die Funktion aus den Regressionen und bestimmt die Abweichungen.
Es ergeben sich die Funktionen: (1-85) 'Beitragszahl=180141/(Rang+3.4402)' und (86-300) 'Beitragszahl=102255/(Rang-34.5739)'

Abbildung 7 - Rekonstruktion der Beitragszahlen aus den Regressionen und Fehlerbetrachtung
Als Fazit kann festgehalten werden, dass es meist schwierig ist, die kritischen Topwerte (Spitzenplätze) mit Hyperbel-Funktionen gut annähern zu können. Es kommt einfach schnell zu riesigen Fehlern (vgl. auch Ergebnisse bei LRM im letzten Artikel). Bei meinen vorherigen Regressionsversuchen traten bei MB unter den Top 10 (trotz Determinationskoeffizienten von deutlich über 0,95) Abweichungen von bis zu 320% auf. Ein Problem, das viele andere Verfahren (selbst Exponentialfunktionen) zumindest nicht in diesem Maße haben. Gelingt es einem jedoch, dies zu umgehen, sind im weiteren Verlauf der kleineren Topgruppe (hier 0-85) meist nur noch Fehler bis zu etwa 15% zu erwarten; das war zuletzt auch bei LRM der Fall. Im späteren Verlauf der Kurven zeigt sich aber (auch bei viel größeren Foren, wie wir jetzt gesehen haben) eine gute Approximation von Zusammenhängen zwischen Rang und Merkmalsausprägung (Punkte, Antworten) durch Hyperbeln. Für diese Werte der Top 300 Gruppe werden bereits Abweichungen von deutlich unter 5% erzielt.
Ein besonderer Vorteil dieses Verfahrens ist nun, dass hunderte Datenpunkte (zumindest innerhalb einer Website) zu "3*n-Datensets" zusammengefasst werden können.
Hierbei steht das n für die Anzahl an Bereichen, die bei der Beschreibung eines Merkmals abgegrenzt werden mussten (hier n=2, wegen zwei Bereichen). Das n sollte für sinnvolle Modelle immer im niedrigen einstelligen Bereich liegen. Die 3 verdeutlicht drei Informationen: 1. Bereichsgrenzen ; 2. a-Wert ; 3 b-Wert (a und b sind die Koeffizienten der allgemeinen Funktion `f(x)=a/(x+b)` ; die Hyperbeln gehen dabei alle aus einfachen Streckungen/Stauchungen und Verschiebungen von `1/x` hervor.)
Mit dieser Modellform können nun Entwicklungen einer Website im zeitlichen Verlauf als Veränderung der "3*n-Datensets" angegeben werden. Mit hinreichend vielen Betrachtungen sind vielleicht sogar schlüssige Prognosen möglich.
Allgemein sind in der Regel auch Exponentialfunktionen (mit negativem Exponenten) zur Modellierung geeignet - was an der Ähnlichkeit im weiteren Verlauf der Funktionen liegt - wenn auch zumindest in diesen Fällen etwas schlechter. Der Vorteil der Exponentialfunktion `f(x)=a*e^(b*x)` ist, dass unterschiedliche Funktionen leichter verglichen werden können (es sind keine Verschiebungen in x-Richtung nötig).
Alle zukünftigen Ergebnisse werde ich, sofern ich überhaupt regelmäßig dazu kommen sollte, in folgender Form angeben:
3*n-Datenset (Beschreibung)
n=1 (Bereichsanfang ; Bereichsende) ; (a-Wert) ; (b-Wert)
n=2 ...
Für diesen Artikel also, obwohl ich mich in Zukunft wohl immer auf LRM beschränken werde:
3*n-Datenset (MatheBoard, Rang zu Anzahl der Beiträge, 21.08.2019 - 14:00 Uhr, Rang 1-300)
n=1 (1 ; 85) ; (180141) ; (3,4402)
n=2 (86 ; 300) ; (102255) ; (-34,5739)
Wer diese Ergebnisse an anderen Seiten überprüfen will, ist gerne dazu eingeladen:
https://www.mathelounge.de/433640/die-grossten-deutschen-matheforen-in-der-ubersicht
Mit freundlichen Grüßen
Valentin Tempel
P.S. Mathelounge (ML) selbst ist bereits ein etwas schwierigerer Fall. ML stellt Punkte (zur Ermittlung der Belohnungen) und Antwortdaten zur Verfügung - ich betrachte nun noch kurz die Punktedaten (da diese leichter nach Rang zu sortieren sind):

Abbildung 8 - ML: Logarithmisch Top 300

Abbildung 9 - Linearisierung: Typ Hyperbel

Abbildung 10 - Linearisierung (Detail), Linearisierungsversuch: Typ Exponentialfunktion
Für die Gruppe ab Rang 100 kann wieder eine sehr gute Hyperbelnäherung gefunden werden. Die Punktzahlen der Top 100 lassen sich aber nicht wirklich mit diesen einfachen Mitteln linearisieren. Man müsste also entweder eine andere Funktion wählen oder für die Top 100 ein großes "3n-Datenset" angeben, was aber eigentlich nicht gewünscht ist.
Student, Punkte: 5.08K
Ich habe für LRM eine neue Sache eingeführt. Den "AP-Score". Das ist der Wert, der sich ergibt, wenn man die Anzahl gegebener Antworten auf LRM mit 10 multipliziert und durch die Punktzahl teilt. Es ergeben sich Werte von min. ca. 0,25 (am besten) bis max. 3,5 (am schlechtesten). Diesen Wert kann man sich als ungefähren Richtwert für die Abweichungen des linearen (eigentlich mit Korrelation zu bestimmenden) Zusammenhangs zwischen abgegebenen Antworten und erreichter Punktzahl vorstellen. Ein Wert von 1 würde bedeuten, für 10 Punkte eine Antwort abgeben zu müssen. Ab einem Wert von 0,7 und darunter ist man erfolgreiches Mitglied (da man nun im Schnitt maximal 0,7 Antworten abgeben musste pro 10 Punkte). Die Grenze ist hierbei eigentlich recht willkürlich gewählt, definiert aber eine kleine Gruppe (unter 20 Nutzer).
Verifizierte Mitglieder sind alle mit einem blauen Haken - also genau wie du. ─ vt5 24.08.2019 um 11:24
Außerdem interessiert mich viel eher die Gesamtpunktzahl, als der künstlich errechnete Wert. Ich weiß z.B. nicht mal ob die Anzahl der abgegeben Antworten wieder sinkt, wenn man eine Frage löscht. Der "AP-Score" ist nur für statistische Auswertungen interessant.
Ich finde es aber allgemein auch angemessen, dass eine Frage mit dem Häkchen geschlossen wird (nicht nur bei mir sondern bei allen Nutzern) wenn eine (passende) Antwort gegeben wurde. ─ vt5 24.08.2019 um 19:02
Interessant, was man so alles aus den Punkten rauslesen kann. Wobei es beim Matheboard ja keine Punkte sind, sondern einfach Beitragszahlen.
Was sind denn eigentlich "erfolgreiche Mitglieder"? Was ist ein "verifiziertes Mitglied"? Zumindest zu letzterem scheine ich zu gehören :P. ─ orthando 22.08.2019 um 22:01