
Angenommen, es soll festgestellt werden, ob es einen Zusammenhang zwischen dem Bildungsgrad und dem Einkommen gibt. Als Hypothesen werden formuliert:
- Nullhypothese: Es gibt keinen Zusammenhang zwischen dem Bildungsgrad und dem Einkommen.
- Alternativhypothese: Es gibt einen Zusammenhang zwischen dem Bildungsgrad und dem Einkommen.
Dazu werden 1270 Personen nach ihrem Bildungsgrad und ihrem Einkommen befragt. Das Ergebnis zeigt Tabelle 1.
Tabelle 1: Einkommen nach Bildungsgrad (fiktive Daten)
\(
\begin{array}{|l|r|r|r|r|}
\hline
\textrm{Einkommen}\times\textrm{Bildung} & \textrm{niedrig} & \textrm{mittel} & \textrm{hoch} & \textrm{Gesamt}\\
\hline
\textrm{niedriges Einkommen} & 240 & 190 & 160 & 590\\
\hline
\textrm{hohes Einkommen} & 90 & 210 & 380 & 680\\
\hline
\textrm{Gesamt} & 330 & 400 & 540 & 1270\\
\hline
\end{array}
\)
1. Stochastische Unabhängigkeit
Zunächst soll ermittelt werden, ob die vorliegenden Stichprobendaten als solche stochastisch unabhängig sind oder nicht. Dazu werden zunächst die unbedingten Stichprobenwahrscheinlichkeiten der Randverteilundgen und der Zellenhäufigkeiten durch die Gleichungen (1) bis (11) ermittelt:
\begin{array}{lcccr}
(1)\qquad{}\textrm{P(Bn)} & = & \frac{330}{1270} & = & 0,2598\\
(2)\qquad{}\textrm{P(Bm)} & = & \frac{400}{1270} & = & 0,3150\\
(3)\qquad{}\textrm{P(Bh)} & = & \frac{540}{1270} & = & 0,4252\\
\hline
\textrm{Summe} & = & \sum_{\textrm{P(Bn)}}^{\textrm{P(Bh)}} & = & 1,0000\\
\hline
(4)\qquad{}\textrm{P(En)} & = & \frac{590}{1270} & = & 0,4646\\
(5)\qquad{}\textrm{P(Eh)} & = & \frac{680}{1270} & = & 0,5354\\
\hline
\textrm{Summe} & = & \sum_{\textrm{P(En)}}^{\textrm{P(Eh)}} & = & 1,0000\\
\hline
(6)\qquad{}\textrm{P(Bn}\cap\textrm{En)} & = & \frac{240}{1270} & = & 0,1890\\
(7)\qquad{}\textrm{P(Bm}\cap\textrm{En)} & = & \frac{190}{1270} & = & 0,1496\\
(8)\qquad{}\textrm{P(Bh}\cap\textrm{En)} & = & \frac{160}{1270} & = & 0,1260\\
(9)\qquad{}\textrm{P(Bn}\cap\textrm{Eh)} & = & \frac{90}{1270} & = & 0,0709\\
(10)\qquad{}\textrm{P(Bm}\cap\textrm{Eh)} & = & \frac{210}{1270} & = & 0,1654\\
(11)\qquad{}\textrm{P(Bh}\cap\textrm{Eh)} & = & \frac{380}{1270} & = & 0,2992\\
\hline
\textrm{Summe} & = & \sum_{\textrm{P(Bn}\cap\textrm{En)}}^{\textrm{P(Bh}\cap\textrm{Eh)}} & = & 1,0000\\
\hline
\end{array}
Der Test auf stochastische Unabhängigkeit für alle sechs unbedingten Zellenwahrscheinlichkeiten ergibt:
\(
\begin{array}{lcccccl|l}
(12)\qquad{}\textrm{P(Bn}\cap\textrm{En)} & \stackrel{!}{=} & \textrm{P(Bn)}\cdot\textrm{P(En)} & \rightarrow & 0,1890 & \neq & 0,1207 & \textrm{nicht unabhängig}\\
(13)\qquad{}\textrm{P(Bm}\cap\textrm{En)} & \stackrel{!}{=} & \textrm{P(Bm})\cdot\textrm{P(En)} & \rightarrow & 0,1496 & \neq & 0,1463 & \textrm{nicht unabhängig}\\
(14)\qquad{}\textrm{P(Bh}\cap\textrm{En)} & \stackrel{!}{=} & \textrm{P(Bh)}\cdot\textrm{P(En)} & \rightarrow & 0,1260 & \neq & 0,1975 & \textrm{nicht unabhängig}\\
(15)\qquad{}\textrm{P(Bn}\cap\textrm{Eh)} & \stackrel{!}{=} & \textrm{P(Bn)}\cdot\textrm{P(Eh)} & \rightarrow & 0,0709 & \neq & 0,1391 & \textrm{nicht unabhängig}\\
(16)\qquad{}\textrm{P(Bm}\cap\textrm{Eh)} & \stackrel{!}{=} & \textrm{P(Bm})\cdot\textrm{P(Eh)} & \rightarrow & 0,1645 & \neq & 0,1686 & \textrm{nicht unabhängig}\\
(17)\qquad{}\textrm{P(Bh}\cap\textrm{Eh)} & \stackrel{!}{=} & \textrm{P(Bh)}\cdot\textrm{P(Eh)} & \rightarrow & 0,2992 & \neq & 0,2277 & \textrm{nicht unabhängig}\\
\end{array}
\)
Das Ausrufungszeichen über dem Gleichheitszeichen heißt, dass die Gleichheit beider Seiten des Terms nur behauptet ist. Genauer: Sochastische Unabhängigkeit zwischen jeweils zwei gleichzeitigen Ereignissen, nämlich dem Auftreten je einer Ausprägung der x- und der y-Variablen (Bildungsgrad und Einkommen) ist genau dann gegeben, wenn die behauptete Gleichheit beider Seiten des Terms wahr ist. Nun zeigt sich, dass stochastische Unabhängigkeit in keiner sechs unbedingten Zellenwahrscheinlichkeiten gegeben ist. Mit anderen Worten: In der Stichprobe besteht ein Zusammenhang zwischen den Variablen Bildungsgrad und Einkommen. Für die Daten der Stichprobe wird die Nullhypothese (stochastische Unabhängigkeit zwischen beiden untersucheten Variablen) zurückgewiesen.
Der Zusammenhang zwischen Bildungsgrad und Einkommen, wie er sich aus den Stichprobendaten ergibt, kann visualisiert werden, wenn eine Tabelle mit relativen Spaltenhäufigkeiten und daraus dann ein segmentiertes und auf 100 Prozent skaliertes Säulendiagramm erstellt wird (siehe Tabelle 2 und Abbildung 1).
Tabelle 2: Relative Spaltenhäufigkeiten der Kontingenztabelle
\(
\begin{array}{|l|r|r|r|r|}
\hline
\textrm{Einkommen}\times\textrm{Bildung} & \textrm{niedrig} & \textrm{mittel} & \textrm{hoch} & \textrm{Gesamt}\\
\hline
\textrm{niedriges Einkommen} & 0,727 & 0,475 & 0,296 & 0,465\\
\hline
\textrm{hohes Einkommen} & 0,273 & 0,525 & 0,704 & 0,535\\
\hline
\textrm{Gesamt} & 1,000 & 1,000 & 1,000 & 1,000\\
\hline
\end{array}
\)
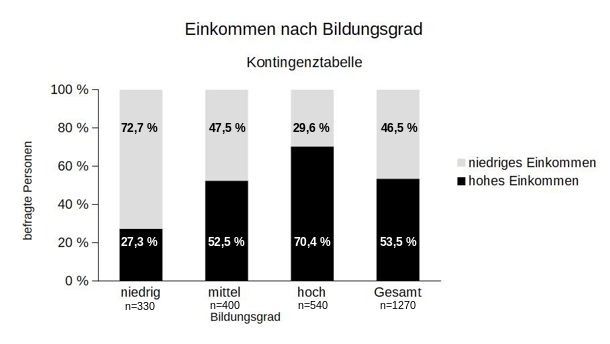
Abbildung 1: Einkommen nach Bildungsgrad (Kontingenztabelle)
2. Chi-Quadrat-Test
Nun stellt sich die Frage, ob der Zusammenhang, der in den Stichprobendaten zu sehen ist, auch in der Grundgesamtheit vorhanden ist oder nicht. Sind die Daten der Stichprobe nur zufällig so wie sie sind? Oder spiegeln sie die Verhältnisse in der Grundgesamtheit wider?
Diese Frage kann nur mit einer gewissen Unsicherheit, einer Wahrscheinlichkeit, beantwortet werden, da wir die Daten der Grundgesamtheit nicht haben. Welche (bedingte) Wahrscheinlichkeit, sich zu irren, wenn angenommen wird, dass es auch in der Grundgesamtheit einen Zusammenhang zwischen Bildungsgrad und Einkommen gibt, sollte unterschritten werden, damit die Nullhypothese (es besteht kein Zusammenhang) zurückgewiesen werden kann? Dieses sogenannte Alpha-Fehler-Niveau [1] ist die Irrtumswahrscheinlichkeit, auf der getestet wird und sollte vor dem Test festgelegt werden.
Wenn die Nullhypothese mit einer Irtumswahrscheinlichkeit unterhalb des festgelegten Alpha-Fehler-Niveaus zurückgewiesen werden kann, dann ist die Annahme, dass der in der Stichprobe festgestellte Zusammenhang auch in der Grundgesamtheit existiert, signifikant. Die Tests mit denen das festgestellt werden kann, heißen deshalb Signifikanztests. Übliche Alpha-Fehler-Niveaus sind 5 Prozent (\(\alpha=0,05\)), 1 Prozent (\(\alpha=0,01\)) und 0,1 Prozent bzw. 1 Promille (\(\alpha=0,001\)). Außerdem geben Tabellenkalkulationen und Statistikprogramme auch die exakte Irrtumswahrscheinlichkeit an, abgeküzt mit \(p\) (für »probability«, das heißt »Wahrscheinlichkeit«).
Der Chi-Quadrat-Test testet nun die Signifikanz, indem die in der Stichprobe beobachteten Zellenhäufigkeiten mit den Zellenhäufigkeiten verglichen werden, wie sie bei gleichen Randhäufigkeiten wären, wenn die beiden Variablen unabhängig voneinander wären. Daraus wird die Testgröße \(\chi^2\) (Chi-Quadrat) berechnet, die dann mit einem theoretischen Tabellenwert verglichen wird. Der Vergleichswert ist abhängig von den Freiheitsgraden und dem vorher festgelegten Alpha-Fehler-Niveau.
Beim Chi-Quadrat-Test sind die Freiheitsgrade die Anzahl an Zellen einer Kreuztabelle, die bei gegebenen Randverteilungen im Rahmen dieser Randverteilungen relativ frei festgelegt werden können, bevor sich alle anderen Zellenhäufigkeiten errechnen lassen. Eine Vierfeldertafel hat, wie leicht nachzuvollziehen ist, genau einen Freiheitsgrad. Allgemein errechnet sich die Anzahl der Freiheitsgrade nach Formel (18):
$$df=(r-1)\cdot(c-1) \tag{18}$$
Dabei steht:
- \(df\) für die Anzahl der Freiheitsgrade (»degrees of freedom«);
- \(r\) für die Anzahl der Zeilen (»row« für Zeile);
- \(c\) für die Anzahl der Spalten (»column« für Spalte).
Tabelle 1 hat daher 2 Freiheitsgrade.
Die in der Stichprobe wirklich beobachteten Zellenhäufigkeiten stehen in Tabelle 1. Wie werden aber die Zellenhäufigkeiten, die erwartet werden können, wenn die beiden Variablen Bildungsgrad und Einkommen voneinander unabhängig wären, bestimmt?
Dazu ist es nötig, sich die Gleichungen (12) bis (17) noch einmal anzuschauen. Hier wird exemplarisch die Gleichung (12) genommen und etwas anders interpretiert. Jetzt haben wir nicht mehr die Behauptung einer Gleichheit, die wahr oder falsch sein kann, sondern eine Definition, die dazu führt, herauszufinden, wie die Zellenhäufigkeiten unter der Annahme der Unabhängigkeit wären. Deshalb ändert sich das Gleichheitszeichen von \(\stackrel{!}{=}\) zu \(\widehat{=}\):
\begin{eqnarray}
\textrm{P(Bn}\cap\textrm{En)} & \widehat{=} & \textrm{P(Bn)}\cdot\textrm{P(En)} \tag{19}
\end{eqnarray}
Gleichung (19) soll so umgeformt werden, dass danach die erwartete Zellenhäufigkeit der Zelle (1.1) bestimmt werden kann. Wenn:
- \(f_{1.1}\) die Zellenhäufigkeit der Zelle (1.1) (niedriger Bildungsgrad und niedriges Einkommen);
- \(n_{.1}\) die Randhäufigkeit für niedrigen Bildungsgrad;
- \(n_{1.}\) die Randhäufigkeit für niedriges Einkommen;
ist, dann kann die unbedingte Wahrscheinlichkeit, dass ein niedriger Bildungsgrad und ein niedriges Einkommen gleichzeitig auftreten und die unbedingten Wahrscheinlichkeiten für die entsprechenden Randhäufigkeiten wie folgt bestimmt werden:
\begin{eqnarray}
\textrm{P(Bn}\cap\textrm{En)} & = & \frac{f_{1.1}}{n}\qquad{}(20) \\
\textrm{P(Bn)} & = & \frac{n_{.1}}{n}\qquad{}(21) \\
\textrm{P(En)} & = & \frac{n_{1.}}{n}\qquad{}(22)
\end{eqnarray}
Daraus folgt:
\begin{eqnarray}
(23)\qquad{}\frac{f_{1.1}}{n} & \widehat{=} & \frac{n_{.1}}{n}\cdot\frac{n_{1.}}{n}\qquad|\cdot n \\
(24)\qquad{}f_{1.1} & \widehat{=} & \frac{n_{.1}\cdot n_{1.}\cdot n}{n\cdot n} \\
(25)\qquad{}f_{1.1} & \widehat{=} & \frac{n_{.1}\cdot n_{1.}}{n}
\end{eqnarray}
Das bedeutet:
Die Zellenhäufigkeiten, wie sie unter der Voraussetzung der Unabhängigkeit der Variablen Bildungsgrad und Einkommen erwartet werden können, werden bestimmt, indem die jeweiligen Randhäufigkeiten miteiander multipliziert werden und dann das Ergebnis durch die Fallzahl dividiert wird. Daher werden diese erwarteten Häufigkeiten so berechnet, wie Tabelle 3 das zeigt.
Tabelle 3: Berechnung der erwarteten Häufigkeiten
\(
\begin{array}{|l|r|r|r|r|}
\hline
\textrm{Einkommen}\times\textrm{Bildung} & \textrm{niedrig} & \textrm{mittel} & \textrm{hoch} & \textrm{Gesamt}\\
\hline
\textrm{niedriges Einkommen} & \frac{590\cdot330}{1270} & \frac{590\cdot400}{1270} & \frac{590\cdot540}{1270} & 590\\
\hline
\textrm{hohes Einkommen} & \frac{680\cdot330}{1270} & \frac{680\cdot400}{1270} & \frac{680\cdot540}{1270} & 680\\
\hline
\textrm{Gesamt} & 330 & 400 & 540 & 1270\\
\hline
\end{array}
\)
Das führt dann zu der folgenden Indifferenztabelle, die die erwarteten Zellenhäufigkeiten enthält:
Tabelle 4: Indifferenztabelle für Einkommen nach Bildungsgrad (fiktive Daten)
\(
\begin{array}{|l|r|r|r|r|}
\hline
\textrm{Einkommen}\times\textrm{Bildung} & \textrm{niedrig} & \textrm{mittel} & \textrm{hoch} & \textrm{Gesamt}\\
\hline
\textrm{niedriges Einkommen} & 153,31 & 185,83 & 250,87 & 590,00\\
\hline
\textrm{hohes Einkommen} & 176,69 & 214,17 & 289,13 & 680,00\\
\hline
\textrm{Gesamt} & 330,00 & 400,00 & 540,00 & 1270,00\\
\hline
\end{array}
\)
Natürlich sind real auftretende Häufigkeiten immer ganze nichtnegative Zahlen. Die erwarteten Häufigkeiten sind jedoch theoretische Werte die der Bestimmung der Testgröße \(\chi^2\) (Chi-Quadrat) dienen. Dass diese Indifferenztabelle tatsächlich Zellenhäufigkeiten zeigt, unter denen die Variablen Bildungsgrad und Einkommen bei gleicher Randverteilung wie in der ursprünglichen Kontingenztabelle tatsächlich voneinander unabhängig wären, ist zu sehen, wenn von der Indifferenztabelle die relativen Spaltenhäufigkeiten gebildet werden und ein entsprechendes Säulendiagramm erstellt wird (Tabelle 5 und Abbildung 2).
Tabelle 5: relative Spaltenhäufigkeiten der Indifferenztabelle
\(
\begin{array}{|l|r|r|r|r|}
\hline
\textrm{Einkommen}\times\textrm{Bildung} & \textrm{niedrig} & \textrm{mittel} & \textrm{hoch} & \textrm{Gesamt}\\
\hline
\textrm{niedriges Einkommen} & 0,465 & 0,465 & 0,465 & 0,465\\
\hline
\textrm{hohes Einkommen} & 0,535 & 0,535 & 0,535 & 0,535\\
\hline
\textrm{Gesamt} & 1,000 & 1,000 & 1,000 & 1,000\\
\hline \end{array}
\)
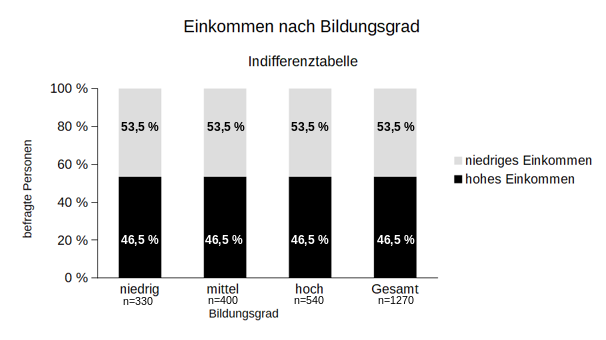
Abbildung 1: Einkommen nach Bildungsgrad (Indifferenztabelle)
Wenn:
- \(f_{b_{i.j}}\) die beobachteteten Zellenhäufigkeiten in der Kontingenztabelle;
- \(f_{e_{i.j}}\) die erwarteten Zelleenhäufigkeiten in der Indifferenztabelle;
- \(i\) der Zeilenzähler;
- \(j\) der Spaltenzähler;
- \(r\) die Anzahl der Zeilen;
- \(c\) die Anzahl der Spalten;
sind, dann wird die Testgröße Chi-Quadrat folgendermaßen berechnet [2]:
$$\sum_{i=1}^{r}\sum_{j=1}^{c}\frac{\left(f_{b_{i.j}}-f_{e_{i.j}}\right)^{2}}{f_{e_{i.j}}} \tag{26}$$
Tabelle 6 zeigt, wie im vorliegenden Fall die Testgröße \(\chi^2\) berechnet wird.
Tabelle 6: Berechnung von Chi-Quadrat
\(
\begin{array}{|l|c|c|c|c|}
\hline
\textrm{Einkommen}\times\textrm{Bildung} & \textrm{niedrig} & \textrm{mittel} & \textrm{hoch} & \textrm{Gesamt}\\
\hline
\textrm{niedriges Einkommen} & \frac{(240-153,31)^{2}}{153,31} & \frac{(190-185,83)^{2}}{185,83} & \frac{(160-250,87)^{2}}{250,87} & \textrm{Summe Zeile 1}\\
\hline
\textrm{hohes Einkommen} & \frac{(90-176,69)^{2}}{176,69} & \frac{(210-214,17)^{2}}{214,17} & \frac{(380-289,13)^{2}}{289,13} & \textrm{Summe Zeile 2}\\
\hline
\textrm{Gesamt} & \textrm{Summe Spalte 1} & \textrm{Summe Spalte 2} & \textrm{Summe Spalte 3} & \chi^{2}\\
\hline
\end{array}
\)
Die Ergebnisse dieser Berechnungen stehen in Tabelle 7.
Tabelle 7: Chi-Quadrat-Tabelle
\(
\begin{array}{|l|r|r|r|r|}
\hline
\textrm{Einkommen}\times\textrm{Bildung} & \textrm{niedrig} & \textrm{mittel} & \textrm{hoch} & \textrm{Gesamt}\\
\hline
\textrm{niedriges Einkommen} & 49,02 & 0,09 & 32,91 & 82,03\\
\hline
\textrm{hohes Einkommen} & 42,54 & 0,08 & 28,56 & 71,17\\
\hline
\textrm{Gesamt} & 91,56 & 0,18 & 61,47 & \mathbf{153,20}\\
\hline
\end{array}
\)
Chi-Quadrat ist also 153,20. Dieser Wert kann auch über die folgende Berechnungstabelle ermittelt werden:
Tabelle 8: Berechnungstabelle für Chi-Quadrat
\(
\begin{array}{|cc|r|r|r|r|r|}
\hline
\textrm{Zeile }i & \textrm{Spalte }j & f_{b_{i.j}} & f_{e_{i.j}} & f_{b_{i.j}}-f_{e_{i.j}} & \left(f_{b_{i.j}}-f_{e_{i.j}}\right)^{2} & \frac{\left(f_{b_{i.j}}-f_{e_{i.j}}\right)^{2}}{f_{e_{i.j}}}\\
\hline
1 & 1 & 240 & 153,31 & 86,69 & 7515,66 & 49,02\\
1 & 2 & 190 & 185,83 & 4,17 & 17,42 & 0,09\\
1 & 3 & 160 & 250,87 & -90,87 & 8256,66 & 32,91\\
2 & 1 & 90 & 176,69 & -86,69 & 7515,66 & 42,54\\
2 & 2 & 210 & 214,17 & -4,17 & 17,42 & 0,08\\
2 & 3 & 380 & 289,13 & 90,87 & 8256,66 & 28,56\\
\hline
\sum\limits _{i=1}^{2} & \sum\limits _{j=1}^{3} & 1270 & 1270,00 & 0,00 & \textrm{(unwichtig)} & 153,20\\
\hline
\end{array}
\)
\(\chi^2=153,20\). Dieser empirische Chi-Quadrat-Wert wird jetzt mit einem Tabellenwert verglichen, der von den Freiheitsgraden und vom gewählten Alpha-Fehler-Niveau abhängt. Solche Tabellen gibt es im Internet und als Anhang in Statistik-Lehrbüchern (vgl. Bortz 2005:817–818, Clauß/Ebner 1968:344, Sahner 1982:178–179). Die folgende Tabelle führt auch das 1-Promille-Niveau auf:
https://www.statistik.tu-dortmund.de/fileadmin/user_upload/Lehrstuehle/Oekonometrie/Lehre/Vorkurs_WS18/tabellechiq.pdf
Bei dieser Tabelle ist erstens zu beachten, dass anders, als das im Tabellenkopf steht, nicht \(\alpha\), sondern \(1-\alpha\) angegeben ist und zweitens hätte über der Spalte mit den Freiheitsgraden eben \(df\) (für »degrees of freedom«) und nicht \(n\) stehen müssen (was eigentlich die Fallzahl ist). Sonst stimmt die Tabelle. In der Tabelle finden sich nun in der Zeile für 2 Freiheitsgrade und den Spalten \(0,95\), \(0,99\) und \(0,999\) für die Alpha-Fehler-Niveaus \(0,05\) (5 Prozent), \(0,01\) (1 Prozent) und \(0,001\) (1 Promille) die folgenden Tabellenwerte:
\(
\begin{array}{lcr}
\chi_{\textrm{Tabelle}(df=2;\alpha=0,05)}^{2} & = & 5,991\qquad{}(27)\\
\chi_{\textrm{Tabelle}(df=2;\alpha=0,01)}^{2} & = & 9,210\qquad{}(28)\\
\chi_{\textrm{Tabelle}(df=2;\alpha=0,001)}^{2} & = & 13,816\qquad{}(29)
\end{array}
\)
Diese Werte gibt auch die Tabellenkalkulatuion aus, wenn die Funktion
=CHIINV([Alpha-Fehler-Niveau];[Freiheitsgrade])
verwendet wird. Der Tabellenwert wird mit dem empirisch ermittelten Chi-Quadrat-Wert verglichen. Nach Clauß/Ebner 1968:197 gilt:
- Wenn \(\chi^2_{\textrm{beobachtet}}<\chi^2_{\textrm{Tabelle}(df;\alpha)}\), dann wird die Nullhypothese angenommen.
- Wenn \(\chi^2_{\textrm{beobachtet}}\geq\chi^2_{\textrm{Tabelle}(df;\alpha)}\), dann wird die Nullhypothese abgelehnt.
In unserem Fall ist der beobachtete Chi-Quadrat-Wert sehr viel größer als alle drei hier in Betracht gezogenen Tabellenwerte. In jedem Fall ist die Nullhypothese abzulehnen und es kann mit sehr hoher Sicherheit angenommen werden, dass der in den Stichprobendaten gefundene Zusammenhang auch in der Realität vorhanden ist.
Sowohl Tabellenkalkulationen als auch Statistikprogramme geben auch die exakte Irrtumswahrscheinlichkeit (Alpha-Fehler) aus. In Statistikprogrammen wird diese Irrtumswahrscheinlichkeit üblicherweise mit \(p\) bezeichnet. Die Ausgabe, die die Tabellenkalkulation in diesem Fall macht, ist
| 5,40028877656116E-34 |
Das heißt \(5,40028877656116\cdot 10^{-34}\). Das ist 0,[34 Nullen]540028877656116. So sicher waren wir uns noch nie. ;-)
3. Die Stärke des Zusammenhangs
Da nun bekannt ist, dass mit einer sehr kleinen Irrtumswahrscheinlichkeit davon ausgegangen werden kann, dass der Zusammenhang zwischen Bildungsgrad und Einkommen auch in der Grundgesamtheit existiert, interessiert die Frage, wie stark dieser Zusammenhang ist. Als Zusammenhangsmaß wird Cramérs V genommen, das nach Benninghaus 1989:109 so definiert ist:
$$V=\sqrt{\frac{\chi^{2}}{n\cdot\textrm{min}(r-1,\:c-1)}} \tag{30}$$
Dabei ist
- \(\chi^2\) der empirisch ermittelte Chi-Quadrat-Wert;
- \(n\) die Fallzahl;
- \(r-1\) die Anzahl der Zeilen minus 1;
- \(c-1\) die Anzahl der Spalten minus 1;
- \(\textrm{min}(r-1,\:c-1)\) die kleinere der Zahlen \(r-1\) oder \(c-1\)
Im vorliegenden Fall ist Cramérs V also:
$$V=\sqrt{\frac{153,20}{1270\cdot1}}=0,347 \tag{31}$$
Das Quadrat davon, also V², ist identisch mit dem Quadrat von Pearsons r. r² wird Determinationskoeffizient oder Bestimmtheitsmaß genannt. Der Determinationskoeffizent gibt an, wieviel der Varianz der abhängigen Variable durch die unabhängige Variable »erklärt« werden kann. Allerdings ist der Determinationskoeffizient symmetrisch. Wenn die Orte, an denen es brennt und die Orte, an denen Feuerwehrleute anzutreffen sind hoch miteinander korrelieren, sagt das noch nicht, ob die Brände die Usache für die Anwesenheit von Feuerwehrleuten oder die Anwesenheit von Feuerwehrleuten die Ursache der Brände ist. Deshalb ist »erklärt« in Anführungszeichen gesetzt.
V², und damit auch r², liegt bei 0,121. Die Varianzaufklärung durch den Determinationskoeffizienten beträgt also 12,1 Prozent. Das ist ein durchaus üblicher Wert.
Anmerkungen
[1]
Wenn die Altenativhypothese angenommen wird, in Wirklichkeit aber die Nullhypothese stimmt, dann ist das ein Alpha-Fehler (Fehler erster Art). Wenn die Nullhypothese angenommen wird, in Wirklichkeit aber die Alternativhypothese stimmt, dann ist das ein Beta-Fehler (Fehler zweiter Art).Vgl. beispielsweise Bortz 2005:110–111, Clauß/Ebner 1968:171–173.
[2]
Die Formel für \(\chi^2\) hat zwei Summenzeichen, weil hier nicht die vorliegenden Fälle, zum Beispiel durchnummerierte Fragebögen, von \(1\) bis \(n\) durchgegangen und dann ein bestimmter Wert aufsummiert wird, sondern es werden die Zellen einer Kreuztabelle durchgegangen und dann beobachtete und erwartete Häufigkeiten in den Zellen summiert.
Um bei einem Schachbrett mit \(r\) Zeilen und \(c\) Spalten und einer zufälligen Verteilung von weißen und schwarzen Feldern, wie in Abbildung 3, herauszufinden, wieviele weiße Felder (\(w_{i.j}\)) es gibt, müssen erst in Zeile \(1\) die weißen Felder in den Spalten \(1\) bis \(c\) addiert werden, dann in Zeile \(2\) usw. bis zu Zeile \(r\):
$$\sum_{i=1}^{r}\sum_{j=1}^{c}w_{i.j} \tag{32}$$
Weil die Summenbildung über \(r\) Zeilen und \(c\) Spalten geht, gibt es zwei Indexvariablen, \(i\) und \(j\) und deshalb zwei Summenzeichen.
Abbildung 3: Das Schachbrett-Modell
Literatur
Benninghaus, Hans, (6)1989: Statistik für Soziologen 1. Deskriptive Statitik. (= Teubner Studienskripten 22, Studienskripten zur Soziologie) Stuttgart: Teubner
Bortz, Jürgen, (6) 2005: Statistik für Human- und Sozialwissenschaftler. Heidelberg: Springer
Clauß, Günter und Heinz Ebner, 1968: Statistik für Psychologen, Pädagogen und Soziologen. Berlin (DDR): Volk und Wissen
Sahner, Heinz, (2)1982: Statistik für Soziologen 2. Induktive Statitik. (= Teubner Studienskripten 23, Studienskripten zur Soziologie) Stuttgart: Teubner
EDIT vom 20.09.2023 um 21:07:
NachtragAm Ende des Artikels steht:
»Das Quadrat davon, also V², ist identisch mit dem Quadrat von Pearsons r.«
Das gilt nur für Vierfeldertafeln. Das bedeutet, dass der folgende Satz so nicht stimmt:
»V², und damit auch r², liegt bei 0,121. Die Varianzaufklärung durch den Determinationskoeffizienten beträgt also 12,1 Prozent. Das ist ein durchaus üblicher Wert.«
Stattdessen müsste dort stehen:
»V² liegt bei 0,121. Würde eine Vierfeldertafel vorliegen, dann läge auch r² bei diesem Wert. Die Varianzaufklärung durch den Determinationskoeffizienten betrüge unter dieser Annahme also 12,1 Prozent. Das ist ein durchaus üblicher Wert.«
Sonstiger Berufsstatus, Punkte: 1.22K